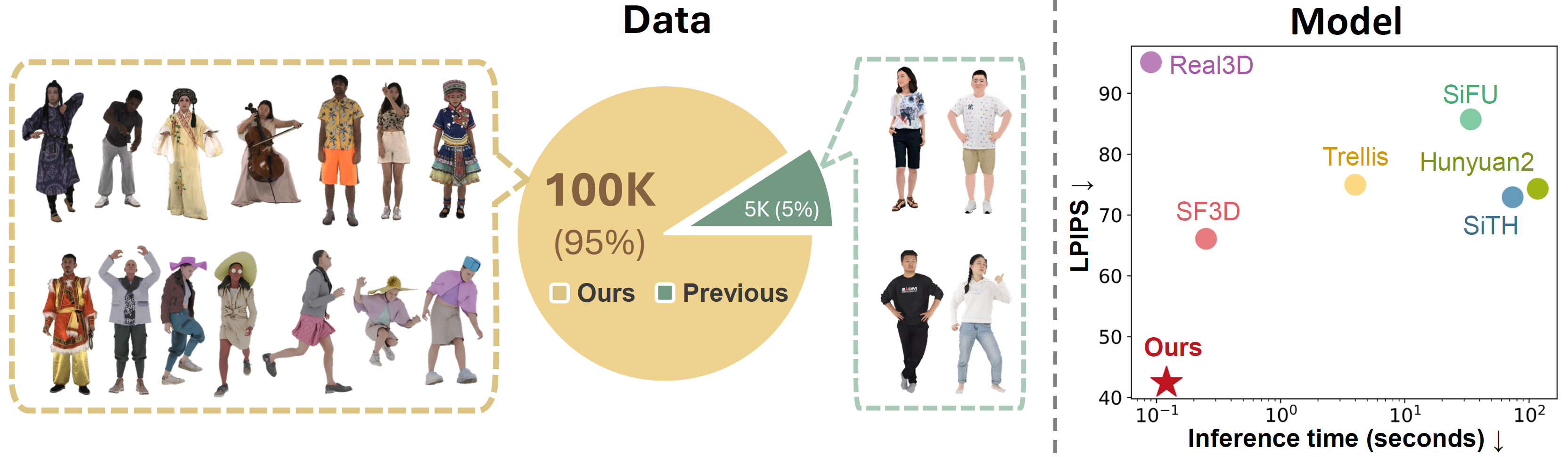
In this paper, we present HumanNOVA, a photorealistic, universal, and rapid model for generating 3D human avatars from a single RGB image. Achieving both photorealism and generalization is challenging due to the scarcity of diverse, high-quality 3D human data. To address this, we build a scalable data generation pipeline that follows two strategies. The first one is to leverage existing rigged assets and animate them with extensive poses from daily life. The second strategy is to utilize existing multi-camera captures of humans and employ fitting to generate more diverse views for training. These two strategies enable us to scale up to 100k assets, significantly enhancing both the quantity and the diversity of data for robust model training. In terms of the architecture, HumanNOVA adopts a feed-forward, token-conditioned avatar modeling framework that allows fast inference in less than one second and requires no test-time optimization. Given an input image and an estimated simplified human mesh (SMPL) without detailed geometry or appearance, the model first encodes both inputs into compact token representations. These tokens then act as conditioning signals and are fused through cross-attention to construct a triplane-based 3D avatar representation. Extensive experiments on multiple benchmarks demonstrate the superiority of our approach, both quantitatively and qualitatively, as well as its robustness under diverse input image conditions.
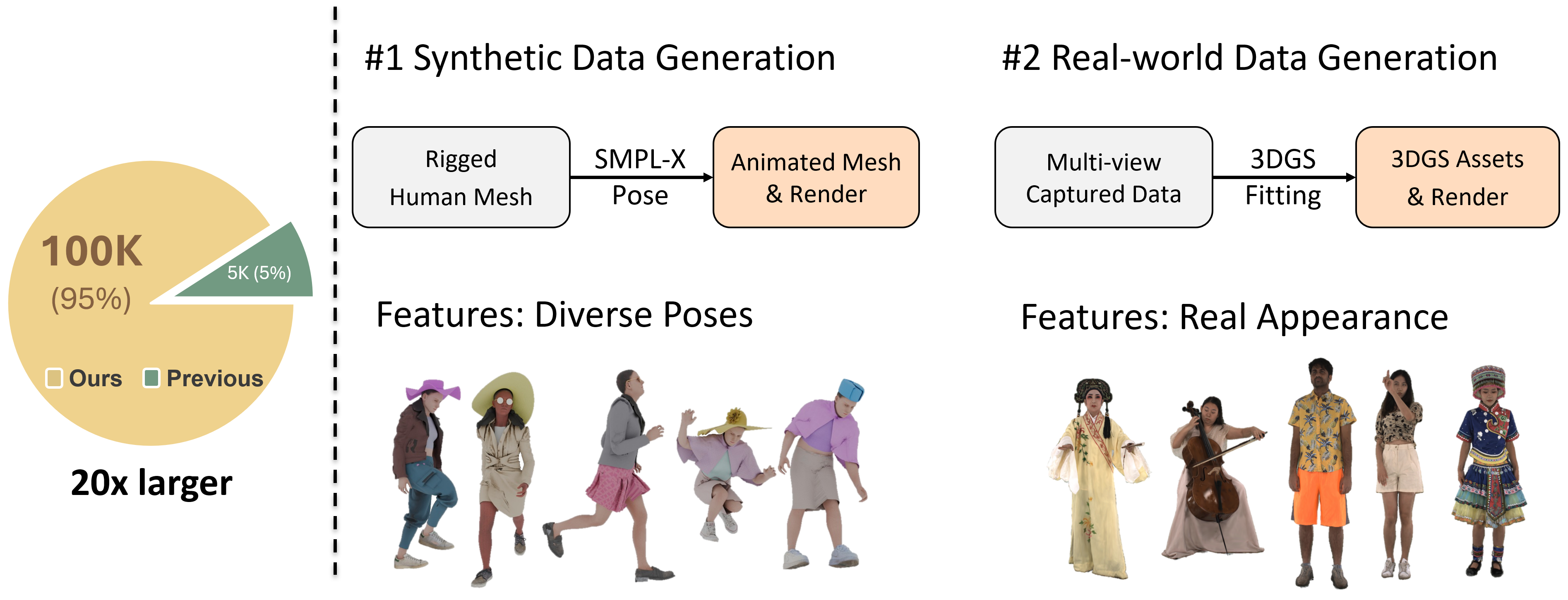
Data generation pipeline. HumanNOVA builds a scalable data generation pipeline to expand the diversity and quantity of training data. We leverage both existing rigged human assets animated with diverse daily poses and multi-camera human captures fitted to generate diverse training views. This enables large-scale training with diverse identities, poses, appearances, and viewpoints.
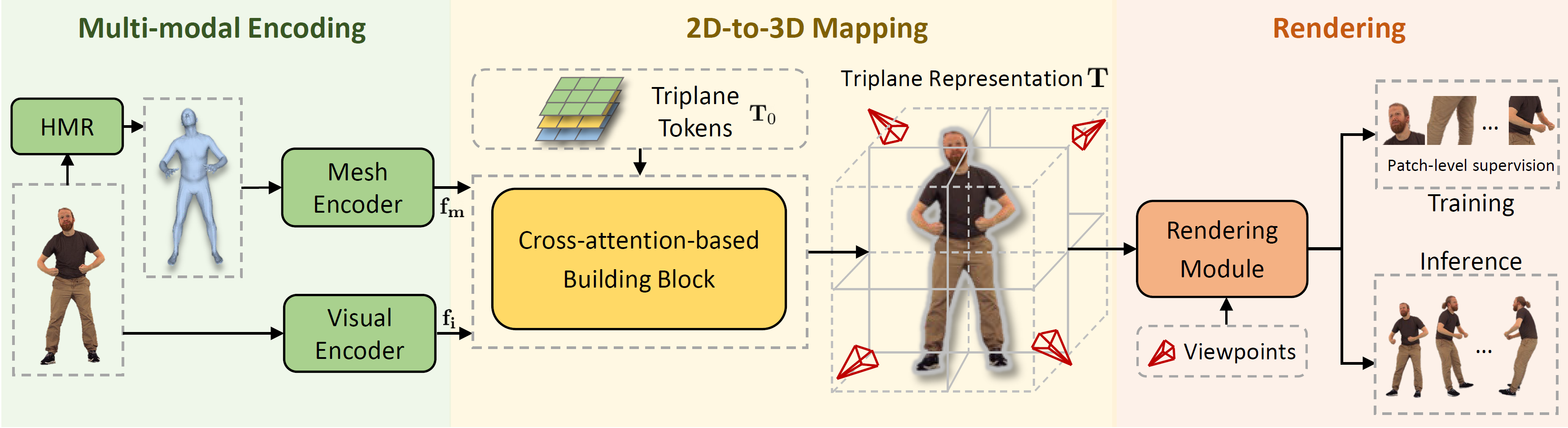
Model architecture. Given a real-world input image, we first estimate its corresponding simplified human mesh. Image and mesh are fed into the multi-modal encoder to extract features, which are utilized as the condition for the following mapping network. After that, a Transformer-based mapping network directly maps the features to the 3D triplane representation. From this triplane representation, our framework can render the 2D image given a camera viewpoint.
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
Input

Our Result
@inproceedings{hu2026humannova,
author = {Hu, Hezhen and Zhao, Wangbo and Guo, Lanqing and Jiang, Hanwen and Liu, Jonathan C. and Fan, Zhiwen and Wang, Kai and Wang, Zhangyang and Pavlakos, Georgios},
title = {{HumanNOVA}: Photorealistic, Universal and Rapid 3D Human Avatar Modeling from a Single Image},
booktitle = {CVPR},
year = {2026},
}